In this document, we will talk about the different problems we have identified in the current data storage and management solutions, and the strategies we are presenting with our software.
Library
People have limited cognitive skills. We can only process a certain volume of information. Wondering how much exactly is like trying to find a needle in a haystack. How big should the haystack be so you can actually find the needle, and from which point onward is the task nearly impossible to execute? We have a relatively small vocabulary in terms of the number of words we can process. If you are looking at a list of 3-4 words, you can see and understand them, and eventually find the one you need. If they are 30 or 40, you may still manage. Should they increase tenfold, you will need to arrange them somehow, otherwise they will be too difficult to work with. When millions of words are involved, the task becomes nearly impossible even if they are ordered.
Because of these limitations of the human brain, we have developed the skill to segment. Arranging the elements of a big dataset in a certain way allows us to split the information into smaller, processable datasets. This can be observed easily today. If you take a lot of photos, you need them somewhat organized or you can never find the one you are looking for. Although people do not handle large datasets very well, they have good pattern recognition skills.
We had books and people used to organize libraries with those books for many years before computers were invented. The primary goal had always been to organize a big set of information (dataset) in a meaningful way, while keeping some elements stand-alone and others – linked (book sequels, for example).
Adding books to a library requires arrangement and re-arrangement every time new titles arrive. This is a demanding operation. You need to put each book in a logical place so that you can find the same book when you need it again. If you leave it at random, almost as if to dispose of it at the time of arrival, there will be no way to find it afterwards.
As the dataset (or the amount of information) keeps on growing, the lack of arrangement at some point will lead to the equivalent of destruction.
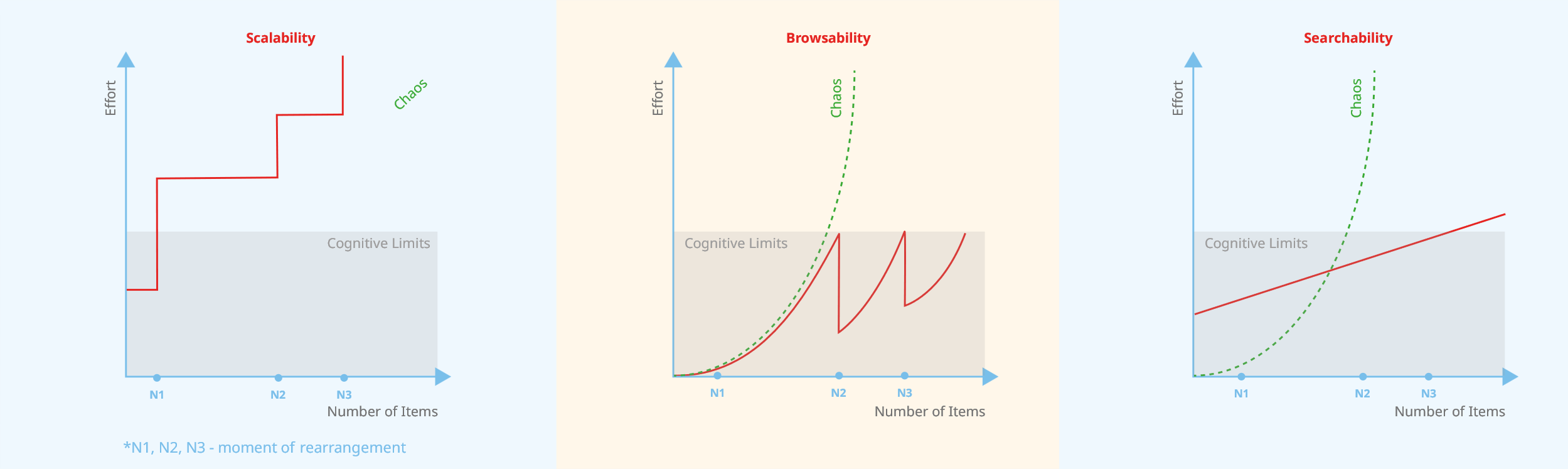
This is why it is so important to look at the different scenarios for data management from the perspective of their searchability, browsability, and scalability. We define the first as the ability to find a specific object or element easily. For example, if you know the name and author of a book, the easier it is to find it, the higher the searchability of the discussed method will be. Browsability, on the other hand, is the ability to browse that same book based on obvious characteristics. For example, you know it included drama and there was a rose on the cover, but you are not sure about the name of the author and the book’s title. If it is easy enough to still find it in such circumstances, then the discussed method has high browsability. Lastly, scalability is the ability to grow a dataset. If you refer to our library example, this is the same as adding a lot of new books and still having room for more.
Hierarchical Data
When computers were invented, people naturally started treating files like books because they had already worked with libraries for a while. It’s not a coincidence that we use the terms “files” and “folders”. It is the easiest way for us to manage information in this day and age.
When you try opening a file, the system will ask you where it is. You will once again need a quick and easy way to browse and find it. Usually, segmentation is achieved with the help of folders and subfolders.

Computers have a significantly higher limit for processing information than the human brain. They become even more effective when indexes are involved. An index keeps track of where each file is located, which makes the identification of an object much easier. People don’t need to arrange the files anymore – they are able to order them exactly the way they like. As long as everything is indexed in the computer, they can find a file whenever it is needed.
From a scalability perspective, if your machine’s hard drive gets full, you should buy a new and larger one. However, the old one will have to be thrown away even though it is still working. It could be disruptive to store parts of your data on two separate drives. Moving it from the old drive to the new is also disruptive and takes time. Chances are, you would rather buy a much larger drive than you actually need at the moment, which would give you buffer and space to grow.
Unstructured Data (Cloud)
With the help of computers and cloud storage, we are able to create and manage much larger volumes of data in an unstructured way, only with the help of an index. This changes the graph shown earlier, because the difficulty of accessing an object is constant and does not depend on the amount of data. Rearrangement, a very heavy operation, is replaced by reindexing, which is much easier to accomplish.
If using computers and unstructured data is so simple, why are we not all doing it?
_1-png.png?width=671&height=201&name=Unstructured_data(cloud)_1-png.png)
As long as you know exactly what you are looking for – they achieve an impressive level of searchability. The system will get the desired object for you in no time. However, browsability – being able to find something even if you are not sure what it is – could be more problematic.
The unstructured and pretty much unlimited data is what the cloud presents with its object storage. However, while using it, you sacrifice browsability for searchability. Some cloud providers allow you to make a file system out of your files in order to get some browsability back, but it would make no sense to do so. When you have an enormous dataset, any additional structures are more likely to be roadblocks rather than solutions. If you don’t have such a dataset, why are you even using the cloud?
Object storage was initially created and is ideal for unlimited, unstructured, and similar scientific data. When dealing with too many almost identical elements, you cannot structure them appropriately, and file systems will typically have limits on the number of objects you may keep per folder. It is not impossible to rise above it, but at some point, your folders will simply stop working when you try to open them. Assuming that happens, you will need to create an artificial structure (like folder 1, folder 2, folder 3) just to separate the objects into different spaces. For a workflows like this, object storage does a great job of keeping your unstructured data by giving you virtually unlimited scalability. This is what modern cloud providers are all about – if you want to use them, embrace zero browsability.
In the scenario where you keep unstructured data and an index in the cloud, it will be possible to add some structure (e.g. a file system) by assigning tags. This way, you can browse for a book in the index which has the “drama” or “thriller” tag. It is like creating a folder with no subfolders – just a single level of hierarchy. Although this could work in some cases, it would be impractical in other.
By adopting the cloud as your data storage location, you add scalability and eliminate the high cost and difficulty associated with rearrangement. The cloud and its scalability concept give you exactly what you need when you need it, and you pay as you go.
Hybrid
From what we’ve discussed so far – object storage is great for some workflows which require unlimited unstructured data. You get the cloud’s benefits in the form of scalability and searchability. However, you sacrifice browsability, which is a problem for on-premises workflows built around it.
Wouldn’t it be great if we could get the best of both worlds – a file system following the human brain’s logic, but with unlimited storage? This is where the hybrid model comes into play. We usually keep hierarchical structured data on-premises for some established workflows. Unstructured and unlimited data is what we have in the cloud. Our solution, Tiger Bridge, can make a hybrid out of these or bridge them together.
If you are not ready to sacrifice browsability for performance, there are two types of hybrid solutions you can potentially create: on-prem first or cloud-first hybrid. Maintaining local workflows for customers played a key role in our decision to build our entire product around the concept of creating an on-prem first hybrid solution. You will see additional reasoning in the following articles.